项目地址: https://github.com/vicalloy/daily-portrait
最近蓄须,每天拍一张照片记录变化,为此衍生出的项目。
- 根据眼睛位置自动对齐照片,并自动生成视频( gif 和 avi )。
- 人脸检测使用 face-recognition 。
- 图片位置修正使用 opencv-python 。

项目地址: https://github.com/vicalloy/daily-portrait
最近蓄须,每天拍一张照片记录变化,为此衍生出的项目。
出于性能的考虑,传统的嵌入式开发都以C、C++为主。如今嵌入式设备的性能早已今非昔比,开发工具的选择方面也有了更大的自由度。对于非性能敏感的业务,Go、Python等开发语言引入的开发速度提升还是非常诱人。Python有着丰富的开发资源,在系统资源足够的情况下,Python在嵌入式环境下有着不错的开发体验。
同Python高效的开发速度相对应的是Python的运行速度非常的慢,即使在脚本语言里Python也是最慢的一档。如果你的程序需要高性能,Python显然是不合适的。即使不需要高性能,也需要特别注意以保证用户体验。
使用的库尽量精简。在PC下Python的启动速度不会有明显的感觉,但在嵌入式设备下,用到的库多了后,第一个明显的感觉就是启动时间变长。如果用到的库多,启动时间甚至会超过10秒。嵌入式环境下引入一个新库需要更为谨慎,平衡好开发体验及性能影响。
Python在跨平台方面做的非常优秀,大多情况下可以不需要嵌入式设备,直接本地开发调试。但程序发布的时候还需要针对应用平台就行打包。
pex会把所有的依赖和你自己的代码打包成一个.pex为后缀的可执行文件。在运行环境下直接执行该文件即可。由于开发环境的构架和运行环境的架构不一致,可以通过Docker容器就行程序的pex打包。
对于商业项目,必要的代码保护还是有一定的必要。代码的保护可以选择下面几种方式。
Python 会自动回收内存,一般情况下不用关心内存的申请和释放问题。事实上我也一直没怎么关心过Python的内存管理问题,直到我用了 Python Prompt Toolkit 。这是一个 Python 的CLI组件库,使用简单,效果很好。只是性能用点差,另外就是它居然有内存泄漏。
Python里内存管理主要基于引用计数实现,另外会辅以全图遍历以解决循环引用问题。一般内存问题都是对象被全局变量直接或间接持有导致。出现内存泄漏后关键是找到问题对象到底被谁给持有了。
如果一个程序内存一直异常增长,那多半是存在内存泄漏。接下来就是定位问题了。Python内存分析的工具和手段主要有下面几个:
gc.get_referents()/gc.get_referents()/gc.* 获取对象的引用计数及指向该对象的对象,以及其它分析函数。
print('PromptSession count: ', len([o for o in obj if isinstance(o, PromptSession)])) 打印对象数量,确认是否被释放。要解决内存问题,关键还是找到存在内存泄漏的问题被谁给持有里,然后在需要销毁对象时释放该持有。如果想该对象持有不影响对象的生命周期(比如缓存),可以使用 weakref 库来创建弱引用。
出于性能等考虑 Python Prompt Toolkit 添加来大量的缓存。其中一些看似简单的缓存对象持有了其它对象的函数(函数指针),从而间接持有了其它对象,最终导致大量的对象未被释放。一般情况下一个程序只有一个 PromptSession 对象,该对象贯穿程序的整个生命周期,因此问题不容易察觉。但我的应用时一个服务端程序,需要反复创建和销毁 PromptSession 对象,问题将出现了。
我尝试用 weakref.WeakValueDictionary 改写它的缓存实现,实际过程中发现key和value都会持有对象。
目前的做法是用户断开服务器连接时进行一次缓存的清理。
近期研究 ONNX Runtime Web 做的一个小东西。很多代码都“借鉴”于其他开源项目,解决了图片变形等问题。
使用深度学习模型做的图片风格迁移。使用 React 和 ONNX Runtime Web 开发,推理后端用的 WebAssembly ( CPU )。根据我的测试,用 WebGL 要慢不少,而且内存占用有些夸张。
在线访问: https://vicalloy.github.io/image-transformer/
项目地址: https://github.com/vicalloy/image-transformer
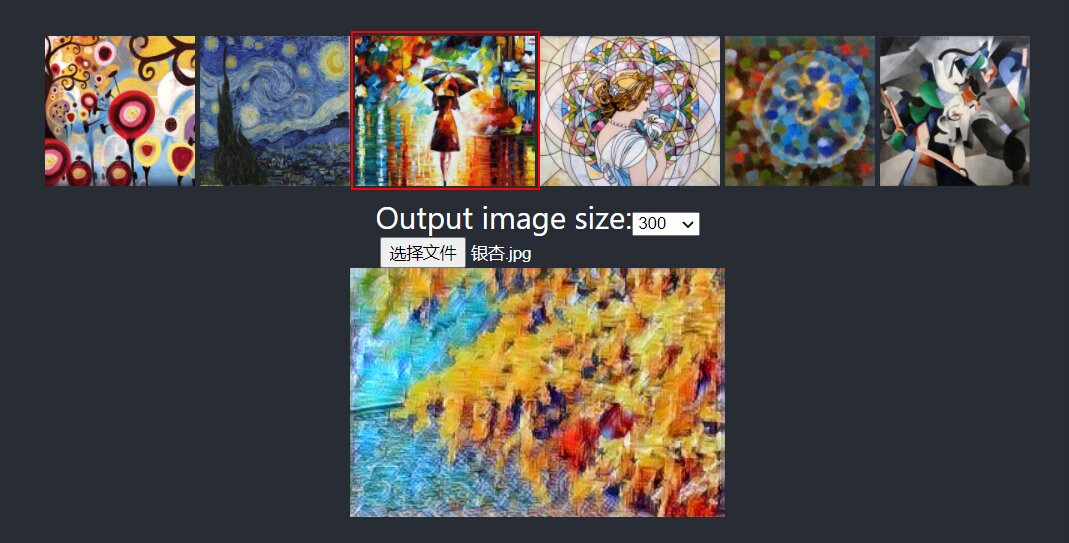
fast neural style这个模型也可以支持输出任意图片大小,不过动态参数模型太大,复杂度也高,不适合 Web 使用。一个类似Pipenv的Python虚拟环境和依赖管理的工具,据称改善了一些Pipenv的问题。对我而言,主要看重了Poetry可以对Python库打包的功能。毕竟对我而言书写 setup.py 并不是一件很让人愉快的事情。
Flake8使用起来非常简单,不用这么配置就可以直接使用,之后检查过程中遇到自己不需要的规则,加个例外就好。
Flake8支持插件,通过添加插件还可以让Flake8功能变的更为强大。
[2023-02 update]: 我的代码检查工具切换成了 ruff 。速度要快很多,且同样易用。
写代码时,我个人会尽量遵守 PEP8 ,但难保团队中有些人代码写的有些随意。为保证编码风格的统一,在代码提交前统一由Black对代码镜像格式化。自动格式化之后的代码可能会少了那么一点个性,但为了统一还是值得的。
Black不会对Python 的 import 语句进行排序和分段,这个工作就交给isort来做了。
长久以来Python作为脚本语言,程序里没有类型信息,很多本可在编译阶段发现的问题被保留到运行时。Python在3.5之后开始支持 Type Hint 了。利用Mypy可以利用这些类型信息对程序进行校验。
相比 unittest ,pytest使用上更为方便。更为重要的是pytest兼容 unittest,似乎没有什么理由来拒绝pytest。
代码覆盖率测试工具好像也没有第二个选择。
在 git commit 时调用flake8进行代码检查,调用black对代码进行格式化等操作。利用pre-commit从源头上杜绝有人把不合格的代码提交到代码库。
CI服务可根据自己的实际情况进行选择
OpenVINO是Intel推出的一款深度学习工具套件。OpenVINO带来大量的预训练模型,使用这些预训练模型可以快速的开发出自己的AI应用。
不过既然是Intel出的东西,自然少不了和Intel平台深度绑定。OpenVINO主要针对Intel的CPU进行优化。虽然也可以支持GPU,但支持的是Intel家的GPU。Intel家的GPU,应当不用报太多期待了。
为了支持更丰富的硬件类型,可以将OpenVINO自带的预训练模型 转为ONNX格式,然后在做其他处理。
OpenVINO优化后的预训练模型无法直接转换为ONNX。不过好在Intel有提供模型的训练和导出工具,利用OpenVINO的训练工具导出ONNX
OpenVINO用于训练和导出的库为: https://github.com/openvinotoolkit/training_extensions 。
具体的操作方式参见项目的具体说明文档。
对照人脸检测的文档,导出人脸检测对应ONNX模型: https://github.com/openvinotoolkit/training_extensions/tree/develop/models/object_detection/model_templates/face-detection
注:导出目录里有 export/,export/alt_ssd_export/ 两种模型。其中 export/alt_ssd_export/ 包含了OpenVINO特有的实现,在转换为其他推理引擎模型时会失败,因此后续工作使用 export/ 中的模型。
对于存在动态shape的模型,TVM无法进行编译。很不幸的是OpenVINO中物体检测相关的模型都存在动态shape。在TVM无法编译的情况下,可使用TVM的VM进行执行。
ONNXRuntime 还要慢不少。不知道是否是跑在虚拟机上的关系。
import onnx
import time
import tvm
import numpy as np
import tvm.relay as relay
target = 'llvm -mcpu=skylake'
model_path = 'face-detection-0200.onnx'
onnx_model = onnx.load(model_path)
shape = [1,3,256,256]
input_name = "image"
shape_dict = {
input_name: shape,
}
mod, params = relay.frontend.from_onnx(onnx_model, shape_dict)
print(relay.transform.DynamicToStatic()(mod))
with tvm.transform.PassContext(opt_level=3):
executable = relay.vm.compile(mod, target="llvm", target_host=None, params=params)
code, lib = executable.save()
with open("code.ro", "wb") as fo:
fo.write(code)
lib.export_library("lib.so")
如果你的模型可以正常编译,那就没必要采用VM模式了。直接编译理论上优化效果要好很多。这里采用的是TVM范例中给出的图片分类模型。
一个完整的模型优化和执行可以参考官方文档:Compiling and Optimizing a Model with the Python AutoScheduler
import onnx
import time
import tvm
import numpy as np
import tvm.relay as relay
target = 'llvm'
model_name = 'mobilenetv2'
model_path = f'{model_name}.onnx'
onnx_model = onnx.load(model_path)
mod, params = relay.frontend.from_onnx(onnx_model)
with relay.build_config(opt_level=3):
graph, lib, params = relay.build(mod, target, params=params)
path_lib = f"./{model_name}.so"
lib.export_library(path_lib)
fo=open(f"./{model_name}.json","w")
fo.write(graph)
fo.close()
fo=open("./{model_name}.params","wb")
fo.write(relay.save_param_dict(params))
fo.close()
加载前面导出的模型,并执行。
import onnx
import time
import tvm
import numpy as np
import tvm.relay as relay
def vmobj_to_array(o, dtype=np.float32):
if isinstance(o, tvm.nd.NDArray):
return [o.asnumpy()]
elif isinstance(o, tvm.runtime.container.ADT):
result = []
for f in o:
result.extend(vmobj_to_array(f, dtype))
return result
else:
raise RuntimeError("Unknown object type: %s" % type(o))
shape = [1, 3, 224, 224]
model_path = 'face-detection-0200'
loaded_lib = tvm.runtime.load_module(f"{model_path}.tvm.so")
loaded_code = bytearray(open(f"{model_path}.tvm.code", "rb").read())
exe = tvm.runtime.vm.Executable.load_exec(loaded_code, loaded_lib)
ctx = tvm.cpu()
vm = tvm.runtime.vm.VirtualMachine(exe, ctx)
data = np.random.uniform(size=shape).astype("float32")
out = vm.run(data)
out = vmobj_to_array(out)
print(out)
近期公司的一个Python程序在启动新进程的时候总是会失败。在进程里可以看到对应的进程已经创建成功,但对应代码并未执行,且没有输入任何日志。
通过定位,发现问题源自Python的logging模块,在写文件模式下,logging模块是不支持多进程的。
Python默认采用Fork方式创建新进程,在Fork新进程的时候会连同 锁 也一同复制到新进程。
Python的logging模块在写文件时会加锁,由于锁被复制导致进程死锁。
注:由于创建新进程时锁会被复制,混用多进程和多线程时的加锁操作应当格外小心。
根据Python的官方文档,logging模块不支持多进程模式下将日志保存到单一日志文件。多进程模式下日志保存方案,建议参考Python官方文档 Logging to a single file from multiple processes 。
Vue.js的使用更接近传统的Web开发,入门门槛比较低。同时双向数据绑定等特性也让Vue.js更为平易近人。在我看来Vue.js为易用性做的妥协在成就了Vue.js的同时,也制约了Vue.js,让他无法变得“伟大”。
在Node.js、React、Vue.js出现后,整个前端的表现能力越来越强,同时也变的越来越复杂。传统依靠jQuery的开发模式已无法支持现在大型SPA应用的开发。相比Vue.js,React这种高度组件化开发框架才更能代表今后前端的发展方向。
之前也看过一些React的相关教程。我一方面认同React的组件开发理念,另一方面又被React繁琐的开发体验劝退(Ant Design Pro早期版本里的登录实现十分劝退)。
近期有机会实际使用了React一段时间。相比初次接触React,现在的TypeScript + React.FC + Hook似乎才是React的完全形态。
React的高度组件化,让代码结构很自然的变的清晰(当然,过细的拆分也让人头痛)。TypeScript让很多潜在错误可以在编译阶段被发现,而且编辑器也开始变的智能很多。Hook的引入,彻底释放了React.FC的能力。相比Class Components使用Function Components的代码实现要简洁很多。
django-lb-workflow 我开发的一个Django流程引擎APP。设计之初是以使用便捷性为目标,自带了完整的模板,希望可以方便的集成到已有系统。尽管已经将django-lb-workflow做到尽量的易用,但距离真正的开箱即用还有一段距离。
Carrot Box是一个完整的Django易用,带了权限管理、部门、角色等必要模块,真正的做到开箱即用。通过对Carrot Box的定制可以方便的改造为OA、工单系统、CRM等业务系统。
Carrot Box的主要特点:
之前的django-lb-workflow范例站点已经切换到 Carrot Box。
管理员账号:admin 密码:password
切换为其他用户: http://wf.haoluobo.com/impersonate/search
退回管理员账号: http://wf.haoluobo.com/impersonate/stop
make init-pyenv
make init
make run
JetBrains的推广活动,解谜后可以获取三个月的免费订阅。由于是推广活动,所以解密过程不是非常难。真正让人头痛的是那糟糕的网速,不管挂不挂代理页面的打开都非常的慢。
48 61 76 65 20 79 6f 75 20 73 65 65 6e 20 74 68 65 20 73 6f 75 72 63 65 20 63 6f 64 65 20 6f 66 20 74 68 65 20 4a 65 74 42 72 61 69 6e 73 20 77 65 62 73 69 74 65 3f
很明显字符串的ASCII码,使用python很容易进行解码
>>> s = "48 61 76 65 20 79 6f 75 20 73 65 65 6e 20 74 68 65 20 73 6f 75 72 63 65 20 63 6f 64 65 20 6f 66 20 74 68 65 20 4a 65 74 42 72 61 69 6e 73 20 77 65 62 73 69 74 65 3f"
>>> ''.join(chr(int(e, 16)) for e in s.split(' '))
'Have you seen the source code of the JetBrains website?'
查看首页源代码找到解谜线索
JetBrains has a lot of products, but there is one that looks like a joke on our Products page, you should start there... (hint: use Chrome Incognito mode)
It’s dangerous to go alone take this key: Good luck! == Jrrg#oxfn$
根据提示,到产品页面。其中名为“JK”的产品介绍是“dare to lean more”,点击该产品继续进行挑战。
注:之前都不知道JetBrains居然已经有这多的产品了。
补完 https://jb.gg/### 后面确实的三个数字。数字为500到5000的质数个数。
到网上找了个求质数的函数,跑了一下,很快得到结果574
import math
def isprime(n):
if n < 2:
return False
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
return False
return True
count = 0
for i in range(500, 5000):
if isprime(i):
count += 1
print(count)
打开上面得到的链接,其中有张图片。图片中的字符为“MPS-31816”
这个题目最坑的在于这个图片实在是太大了,约有15M,死活打不开。
https://www.jetbrains.com/MPS-31816 显示没有这个网页。MPS-31816 在JetBrains 网站找到对应页面。注:后续会知道图片上的图标是JebBrains网站的问题区的Logo。
“The key is to think back to the beginning.” – The JetBrains Quest team
Qlfh$#Li#|rx#duh#uhdglqj#wklv#|rx#pxvw#kdyh#zrunhg#rxw#krz#wr#ghfu|sw#lw1#Wklv#lv#rxu#lvvxh#wudfnhu#ghvljqhg#iru#djloh#whdpv1#Lw#lv#iuhh#iru#xs#wr#6#xvhuv#lq#Forxg#dqg#iru#43#xvhuv#lq#Vwdqgdorqh/#vr#li#|rx#zdqw#wr#jlyh#lw#d#jr#lq#|rxu#whdp#wkhq#zh#wrwdoo|#uhfrpphqg#lw1#|rx#kdyh#ilqlvkhg#wkh#iluvw#Txhvw/#qrz#lw“v#wlph#wr#uhghhp#|rxu#iluvw#sul}h1#Wkh#frgh#iru#wkh#iluvw#txhvw#lv#‟WkhGulyhWrGhyhors†1#Jr#wr#wkh#Txhvw#Sdjh#dqg#xvh#wkh#frgh#wr#fodlp#|rxu#sul}h1#kwwsv=22zzz1mhweudlqv1frp2surpr2txhvw2
很明显要用到之前的 take this key: Good luck! == Jrrg#oxfn$ 。我一开始将问题想的太复杂了,以为第一题里的内容是密钥,用xor进行解密。在网上找了个xor解密的函数,解出来一塌糊涂。
由回头仔细看了一下这所谓的密码,其实就是一个简单的字映射。
>>> s = "Qlfh$#Li#|rx#duh#uhdglqj#wklv#|rx#pxvw#kdyh#zrunhg#rxw#krz#wr#ghfu|sw#lw1#Wklv#lv#rxu#lvvxh#wudfnhu#ghvljqhg#iru#djloh#whdpv1#Lw#lv#iuhh#iru#xs#wr#6#xvhuv#lq#Forxg#dq
g#iru#43#xvhuv#lq#Vwdqgdorqh/#vr#li#|rx#zdqw#wr#jlyh#lw#d#jr#lq#|rxu#whdp#wkhq#zh#wrwdoo|#uhfrpphqg#lw1#|rx#kdyh#ilqlvkhg#wkh#iluvw#Txhvw/#qrz#lw“v#wlph#wr#uhghhp#|rxu#iluvw#s
ul}h1#Wkh#frgh#iru#wkh#iluvw#txhvw#lv#‟WkhGulyhWrGhyhors†1#Jr#wr#wkh#Txhvw#Sdjh#dqg#xvh#wkh#frgh#wr#fodlp#|rxu#sul}h1#kwwsv=22zzz1mhweudlqv1frp2surpr2txhvw2"
>>>
>>> c = ord('J') - ord('G')
>>> ''.join(chr(ord(e) - c) for e in s)
'Nice! If you are reading this you must have worked out how to decrypt it. This is our issue tracker designed for agile teams. It is free for up to 3 users in Cloud and for 10
users in Standalone, so if you want to give it a go in your team then we totally recommend it. you have finished the first Quest, now it’s time to redeem your first prize. Th
e code for the first quest is “TheDriveToDevelop”. Go to the Quest Page and use the code to claim your prize. https://www.jetbrains.com/promo/quest/'